La differenza tra misurare e simulare
La maggior parte delle strategie GEO funziona in reattivo: pubblica, aspetta, misura, ottimizza. Il ciclo di feedback dura settimane.
Esiste un approccio alternativo: simulare il comportamento dei modelli prima di pubblicare. Invece di aspettare di sapere se un contenuto verrà citato, si usa il modello stesso come strumento di test — interrogandolo direttamente sulle query target. Il reverse engineering della GEO trasforma la strategia da reattiva a proattiva.
La maggior parte delle strategie GEO funziona come un giocatore inesperto: pubblica contenuti, aspetta che i modelli li indicizzino, misura le citazioni dopo settimane o mesi, e poi ottimizza. Il ciclo di feedback è lungo e lento.
Il reverse engineering della GEO introduce una logica diversa: simulare il comportamento dei modelli prima di pubblicare. Invece di aspettare di sapere se un contenuto verrà citato, si usa il modello stesso come strumento di test — chiedendogli direttamente come risponderebbe a una query e quali fonti userebbe.
Questa inversione — da reattiva a proattiva — è resa possibile da un fatto tecnico fondamentale: i modelli linguistici sono sistemi deterministici con comportamenti prevedibili. Le stesse strutture di contenuto che generano citazioni in produzione sono le stesse che i modelli usano come fonti quando vengono interrogati direttamente.
Tecnica 1: Prompt testing diretto
Il prompt testing diretto è la tecnica più immediata e potente del reverse engineering. Consiste nel chiedere al modello — esplicitamente — cosa direbbe a un utente che pone una specifica query, e analizzare la risposta per capire quali fonti e strutture privilegia.
Il protocollo si articola in tre fasi.
Fase 1 — Query di scenario: poni al modello la query target senza preamboli e osserva la risposta naturale. Identifica: quali concetti vengono trattati, in quale ordine, con quale livello di dettaglio, quali fonti vengono citate (se il modello le cita), quali entità vengono associati al topic.
Fase 2 — Probe sulle fonti: dopo la risposta iniziale, chiedi esplicitamente: “Quali fonti o siti web useresti come riferimento per rispondere a questa domanda?” Le risposte rivelano la gerarchia implicita delle fonti autorevoli per quel topic nella rappresentazione interna del modello.
Fase 3 — Test del proprio contenuto: condividi il tuo contenuto con il modello e chiedi: “Se dovessi sintetizzare questo contenuto per rispondere alla query [X], quale parte useresti? Manca qualcosa di essenziale?” Questo fornisce feedback diretto e specifico sulla struttura del contenuto.
| Domanda di probe | Cosa rivela | Azione conseguente |
| “Quali siti citeresti per rispondere a [query]?” | Gerarchia di autorevolezza per quel topic nella percezione del modello | Analizzare i siti citati e identificare i pattern strutturali vincenti |
| “Il mio contenuto è adeguato per rispondere a [query]?” | Gap tra struttura attuale e struttura ideale per il retrieval | Ristrutturare le sezioni carenti identificate dal modello |
| “Cosa aggiungeresti a questo contenuto?” | Topic e sotto-query non ancora coperti dal contenuto | Integrare le sezioni mancanti suggerite |
| “Questo paragrafo è sufficiente per rispondere a [sotto-query]?” | Qualità del chunk come risposta autonoma | Riscrivere il chunk per migliorare la completezza autonoma |
Tecnica 2: Chunk testing e self-consistency
Il chunk testing verifica se un paragrafo specifico viene riprodotto fidelmente nelle risposte del modello — indicando che il modello lo tratta come un chunk semanticamente completo e citabile.
Il test: poni al modello una domanda a cui quel paragrafo dovrebbe rispondere, e osserva se la risposta rispecchia la struttura e il contenuto del paragrafo o se il modello lo rielabora significativamente. Un chunk che viene riprodotto fedelmente nella struttura logica (anche non verbatim) è un chunk ben formato per il retrieval.
La variante più avanzata è il self-consistency test: poni la stessa query 5-10 volte al modello (con temperature alta o con leggere variazioni nella formulazione) e osserva la variabilità delle risposte. Un topic per cui il modello produce risposte molto simili in ogni iterazione indica forte consenso semantico — il modello ha una rappresentazione stabile e consolidata. Un topic con alta variabilità nelle risposte indica representing uncertainty — il modello non ha fonti chiare di riferimento, aprendo uno spazio di opportunità per diventare la fonte canonica.
Tecnica 3: Competitive deconstruction
La competitive deconstruction è una delle tecniche più potenti per identificare i pattern vincenti nel proprio settore. Invece di analizzare il proprio contenuto, si usa il modello per capire perché i contenuti dei competitor vengono citati.
Il protocollo: chiedi al modello di descrivere il competitor più citato nel tuo settore per le query target (“Cosa sai dell’azienda X? Perché è considerata autorevole su [topic]?”). La risposta rivela:
Quali attributi il modello associa all’autorità del competitor su quel topic
Quali terminologie specifiche il modello usa per descrivere la loro specializzazione
Quali tipi di contenuto o fonti il modello cita come evidenza della loro competenza
Successivamente, chiedi al modello di confrontare esplicitamente il proprio brand con il competitor su quel topic: “Come si confrontano [Brand A] e [Brand B] su [topic]?”. L’analisi delle differenze nella descrizione rivela esattamente dove il proprio posizionamento semantico è più debole rispetto alla concorrenza — e quindi dove intervenire.
Tecnica 4: Source citation analysis
La source citation analysis si applica alle piattaforme che forniscono fonti citate nelle risposte (Perplexity, Bing Copilot, Google AI Mode con link). Invece di analizzare le risposte in forma testuale, si analizzano gli URL citati come fonti.
L’analisi si articola su tre livelli:
Analisi di dominio: quali siti vengono citati più frequentemente per le query target? Costruire una classifica per frequenza di citazione rivela la gerarchia di autorevolezza percepita dal sistema per quel topic.
Analisi di pagina: quali specifiche pagine all’interno dei siti più citati vengono scelte? Analizzare la struttura, il formato e il contenuto di queste pagine permette di identificare i pattern tecnici e editoriali vincenti.
Analisi temporale: i siti citati tendono a essere recentemente aggiornati? Tendono ad avere date esplicite? Identificare la sensibilità temporale del sistema per quel topic aiuta a calibrare la frequenza di aggiornamento dei propri contenuti.
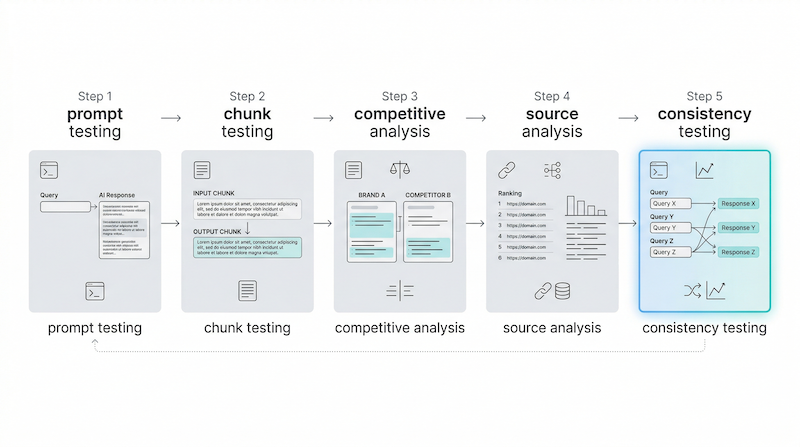
Tecnica 5: Response consistency testing e gap mapping
Il response consistency testing testa la stabilità della risposta del modello su varianti semantiche della stessa query. L’obiettivo è identificare dove il modello è incerto — e trasformare quella incertezza in opportunità.
Il metodo: costruisce una famiglia di 8-12 varianti della stessa query target (sinonimi, riformulazioni, varianti di stile, aggiunta di contesto) e le testa tutte. Le domande da analizzare:
Le risposte convergono sulle stesse fonti? O cambia il set di fonti citate al variare della formulazione?
Il contenuto delle risposte è coerente o varia significativamente tra varianti?
Ci sono varianti per cui la risposta è chiaramente meno soddisfacente (più vaga, meno specifica, con meno fonti)?
Le varianti con risposte meno soddisfacenti e fonti più variabili sono i punti di ingresso ideali: il modello non ha ancora una fonte canonica per quella specifica formulazione dell’intento. Un contenuto ottimizzato per quella variante può diventare la fonte di riferimento più velocemente rispetto a varianti già presidiate dalla concorrenza.
Il ciclo iterativo: dal test alla pubblicazione al test
Il reverse engineering è più efficace come pratica iterativa che come analisi una tantum. Il ciclo ottimale si articola in quattro passi ripetuti ogni 4-6 settimane.
| Passo | Attività | Output |
| 1. Test | Prompt testing + source citation analysis per topic prioritari | Mappa dei gap: cosa manca, quale struttura funziona, chi sono le fonti citate |
| 2. Produzione | Creazione contenuti ottimizzati sulla base dei gap identificati | Contenuto pubblicato con struttura validata dal reverse engineering |
| 3. Ri-test | Chunk testing del contenuto pubblicato su query target | Valutazione della qualità del chunk: viene riprodotto? Viene migliorato? |
| 4. Ottimizzazione | Aggiustamento delle sezioni deboli identificate nel ri-test | Contenuto ottimizzato pronto per monitoraggio nel sistema di tracking GEO |
La frequenza ottimale del ciclo dipende dalla velocità del settore: mercati con alta frequenza di aggiornamento delle informazioni (tecnologia, finanza, normative) richiedono cicli più brevi. Settori stabili (manifatturiero tradizionale, artigianato) possono operare su cicli trimestrali.
Limiti etici e tecnici del reverse engineering
Il reverse engineering della GEO ha limiti tecnici ed etici da rispettare.
Limite 1 — Non è possibilità di accesso al modello: le tecniche descritte interagiscono con il comportamento osservabile dei modelli, non con i loro parametri interni. Non è “hackerare” il sistema — è osservare sistematicamente il comportamento pubblico per trarne inferenze.
Limite 2 — I modelli non rispecchiano perfettamente il retrieval: le risposte di un modello quando viene interrogato direttamente su quali fonti userebbe non corrispondono perfettamente al retrieval in produzione. Sono un proxy utile, non una certezza. Il testing diretto delle query in produzione rimane necessario.
Limite 3 — Etica della simulazione: il reverse engineering non deve essere usato per costruire contenuti che ingannano i modelli — facendo apparire un’azienda come autorevole su topic su cui non lo è. Oltre all’impatto reputazionale, i modelli hanno sistemi di rilevamento sempre più sofisticati per contenuti ottimizzati artificialmente.
Il reverse engineering è uno strumento per rendere visibile ai modelli un’autorità reale che esiste ma che non è ancora rappresentata adeguatamente nei loro dataset. Non è uno strumento per costruire un’autorità artificiale.
| 🔬 Applica il reverse engineering oggi stesso
Scegli le 3 query più importanti per il tuo business. Aprile su Perplexity e ChatGPT. Chiedi: “Quali siti useresti come fonte per rispondere a questa domanda?” Registra le risposte. Analizza i pattern dei siti citati. Hai appena eseguito il tuo primo reverse engineering della GEO in meno di 30 minuti. |
Integrazione con il sistema di misurazione: il circolo virtuoso
Il reverse engineering non è una pratica isolata — è il motore del circolo virtuoso della misurazione GEO. Si integra con le pratiche descritte nei capitoli precedenti della Parte IV in un sistema coerente.
Il sistema di tracking del capitolo 13 (→ Cap. 13) fornisce i dati di citazione reale. La mappa di attribuzione del capitolo 14 (→ Cap. 14) trasforma quei dati in una mappa strategica. Il reverse engineering del presente capitolo permette di ottimizzare i contenuti prima che entrino nel ciclo di tracking.
Il flusso operativo completo: Reverse Engineering → Produzione Ottimizzata → Tracking → Attribuzione → Nuovo Gap Identificato → Reverse Engineering. Ogni ciclo produce contenuti progressivamente più allineati al comportamento dei modelli.
Casi d’uso settoriali: come applicare il reverse engineering
Le tecniche di reverse engineering si applicano in modo diverso a seconda del settore e del tipo di query target.
B2B Services: il focus è su query comparative e di valutazione (“come scegliere un fornitore di X”, “differenza tra Y e Z”). Il competitive deconstruction è particolarmente efficace — i modelli tendono ad avere rappresentazioni chiare dei player principali in questi settori.
E-commerce: le query target sono spesso informative pre-acquisto (“qual è il miglior prodotto per X”, “come funziona Y”). Il chunk testing è critico: i modelli estraggono informazioni di prodotto da fonti diverse e il formato delle schede prodotto deve essere ottimizzato per questo retrieval.
Healthcare e YMYL: il reverse engineering rivela l’importanza straordinaria delle credenziali E-E-A-T in questi settori. I modelli citano quasi esclusivamente fonti con autori identificati, credenziali verificabili e aggiornamento recente. Il source citation analysis è fondamentale per capire gli standard minimi di autorevolezza richiesti.
Content Marketing e Media: il self-consistency testing è particolarmente rilevante — per topic di attualità o opinione, i modelli hanno alta variabilità nelle risposte, il che significa che la finestra di opportunità per diventare fonte canonica è più aperta rispetto a topic con forte consenso consolidato.
| → Prossima sezione: Strategia Organizzativa (Parte V)
Con la Parte IV completata, il manuale ha coperto come misurare, attribuire e simulare la visibilità generativa. La Parte V — Capitolo 16 (→ Cap. 16) affronta la dimensione organizzativa: come trasformare il team SEO in un team di Authority & Relevance capace di operare in modo nativo nell’ecosistema AI Search. |
| ❓ FAQ — Domande frequenti sul reverse engineering GEO
Cos’è il reverse engineering nella GEO e come si differenzia dalla misurazione standard? La misurazione standard registra a posteriori dove il brand è stato citato. Il reverse engineering è un approccio a priori: invece di aspettare che i contenuti vengano indicizzati e citati, si usa il modello come strumento di test diretto per capire se e come un contenuto verrà usato come fonte. Le 5 tecniche principali sono: prompt testing diretto, chunk testing, competitive deconstruction, source citation analysis e response consistency testing. Come si usa il prompt testing per ottimizzare i contenuti prima della pubblicazione? Il protocollo prevede tre fasi: query naturale (poni al modello la query target e osserva la risposta naturale), probe sulle fonti (chiedi esplicitamente quali siti userebbe come riferimento), test del contenuto (condividi il tuo contenuto e chiedi al modello se è adeguato per rispondere alla query e cosa manca). Le risposte forniscono feedback diretto sulla struttura e i gap del contenuto. Il self-consistency testing è affidabile come metrica di opportunità? Il self-consistency testing — porre la stessa query 5-10 volte con leggere variazioni e osservare la variabilità delle risposte — è un proxy affidabile del livello di consenso semantico del modello su quel topic. Alta variabilità significa che il modello non ha fonti canoniche chiare, indicando maggiore opportunità per un nuovo contenuto ben strutturato di diventare la fonte di riferimento. Non è una certezza, ma è un indicatore utile per la prioritizzazione editoriale. Ci sono rischi etici nel reverse engineering della GEO? Il reverse engineering è etico quando viene usato per rendere visibile ai modelli un’autorità reale che esiste ma che non è ancora rappresentata adeguatamente. Non è etico quando viene usato per costruire un’apparenza di autorità artificiale su topic su cui il brand non ha competenza reale. Oltre all’impatto reputazionale, i modelli hanno sistemi di rilevamento sempre più sofisticati per contenuti ottimizzati artificialmente senza sostanza reale dietro. Con quale frequenza va eseguito il ciclo di reverse engineering? Il ciclo ottimale — test, produzione, ri-test, ottimizzazione — ha una frequenza di 4-6 settimane per la maggior parte dei settori. Mercati con alta frequenza di aggiornamento (tecnologia, finanza, normative) richiedono cicli più brevi (2-3 settimane). Settori stabili possono operare su cicli trimestrali. La frequenza deve essere sostenibile internamente: meglio un ciclo mensile eseguito con cura di un ciclo settimanale superficiale. |
Appendice A — Link interni: anchor e motivazioni
| Cap. | Anchor usato | Motivazione editoriale |
| 13 | “sistema di tracking del capitolo 13” | Il tracking fornisce i dati di citazione reale su cui il reverse engineering lavora |
| 14 | “mappa di attribuzione del capitolo 14” | L’attribuzione entità-topic è il framework analitico che il reverse engineering alimenta e affina |
| 16 | “Parte V — Capitolo 16” (nel CTA finale) | Transizione strutturale dalla Parte IV (misurazione) alla Parte V (organizzazione) |
Appendice B — Fonti citate
| # | Autore / Organizzazione | Titolo | Anno |
| [1] | Aggarwal et al. | GEO: Generative Engine Optimization — arXiv:2311.09735 | 2023 |
| [2] | OpenAI | GPT-4 Technical Report — System Card and Behavior Analysis | 2024 |
| [3] | Peec.ai Research | Reverse Engineering AI Search: Citation Patterns in Generative Responses | 2024 |
| [4] | Perplexity AI | How Perplexity Cites Sources: Retrieval Architecture Overview | 2024 |