Quando un utente interroga un sistema AI Search, il sistema non esegue una ricerca — ne esegue diverse. In modo automatico, invisibile, senza che l’interfaccia lo dichiari.
Questo processo — il query fan-out — è uno dei meccanismi più importanti e meno discussi dell’AI Search moderno. Capirlo cambia radicalmente come si pensa alla struttura di un contenuto: non si tratta più di rispondere a una domanda, ma di rispondere all’intera costellazione di domande implicite che quella domanda porta con sé. I contenuti che mappano questa costellazione in modo sistematico emergono nella risposta AI con una frequenza che non è casuale — è il risultato diretto di una copertura semantica intenzionale. L’intent orchestration analizzata nel capitolo dedicato a come le keyword evolvono verso l’orchestrazione dell’intenzione trova qui la sua implementazione tecnica concreta.
Cos’è il query fan-out: definizione e meccanismo
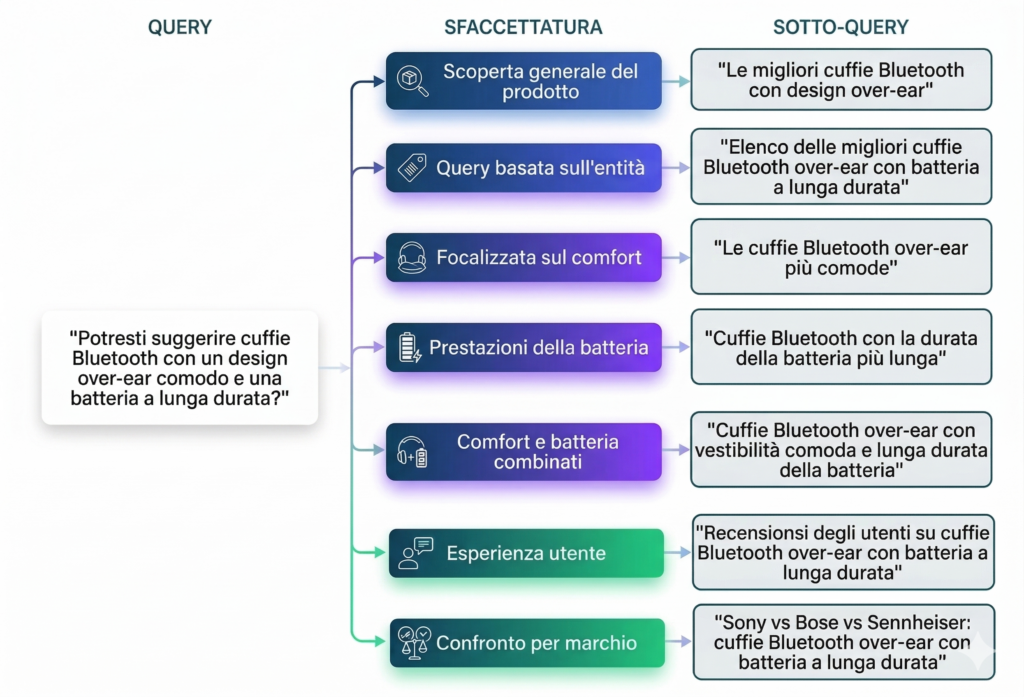
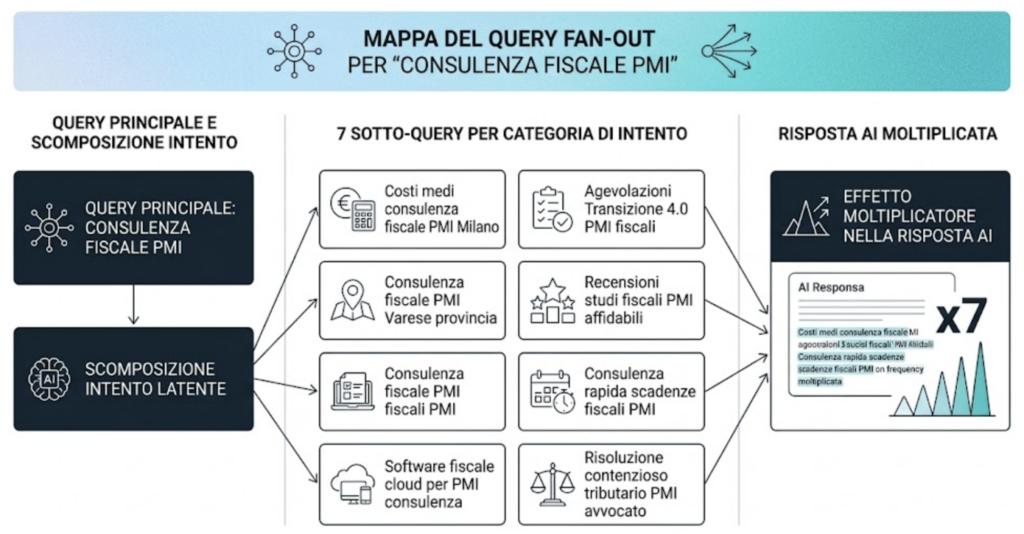
Il query fan-out è il processo attraverso cui un sistema AI Search scompone una query utente in un insieme di sotto-query atomiche — ciascuna delle quali viene eseguita separatamente sull’indice o sul corpus di retrieval. Le sotto-query generate coprono dimensioni diverse dello stesso intento: la dimensione definitoria (cos’è X?), la dimensione comparativa (X vs Y), la dimensione procedurale (come fare X), la dimensione contestuale (X per il mio caso specifico), la dimensione temporale (X nel 2025 vs 2023). I risultati delle sotto-query vengono poi aggregati e sintetizzati dal modello linguistico in una risposta coerente.
La ragione per cui il query fan-out esiste è semplice: le query utente sono parziali per definizione. Un utente che cerca “miglior laptop per video editing” non esplicita che vuole sapere anche il prezzo, la durata della batteria, il confronto tra modelli Windows e Mac, la compatibilità con software specifici. Ma queste sono domande che sta implicitamente ponendo — e un sistema AI che le ignorasse produrrebbe una risposta incompleta. Il fan-out è il meccanismo che permette all’AI di essere proattiva nell’anticipare i bisogni informativi impliciti.
Il numero di sotto-query generate varia in base alla complessità dell’intento: query semplici e transazionali (“prezzo iPhone 15”) generano 2-3 sotto-query; query informative complesse (“come investire 50.000 euro in modo sicuro”) possono generare 8-12 sotto-query su dimensioni molto diverse (rischio, rendimento, strumenti finanziari, regime fiscale, orizzonte temporale, profilo dell’investitore).
Le tipologie di intento latente: mappa delle sotto-query implicite
Per costruire un contenuto che massimizza la copertura del query fan-out, bisogna sapere quali tipologie di intento latente un sistema AI tipicamente genera per ogni query. L’analisi empirica di query in diversi settori rivela sei categorie ricorrenti di sotto-query implicite.
- Intento definitorio. “Cos’è X?” — il sistema genera sempre una sotto-query che cerca la definizione del concetto principale. Anche se l’utente non ha chiesto una definizione, il sistema la include nella risposta per contestualizzare. Un contenuto che contiene una definizione precisa di X nei primi paragrafi ha alta probabilità di essere citato per questa sotto-query.
- Intento comparativo. “X vs Y”, “alternative a X” — il sistema cerca contenuti che confrontano il soggetto della query con alternative o competitor. Tabelle comparative, sezioni dedicate al confronto e FAQ su differenze tra varianti rispondono a questo intento.
- Intento procedurale. “Come fare X”, “guida passo per passo a X” — il sistema cerca contenuti con istruzioni operative. Sezioni HowTo strutturate, liste numerate di step, guide con risultati attesi rispondono a questo intento.
- Intento contestuale. “X per [profilo specifico]” — il sistema adatta la risposta al contesto dell’utente (professionale, principiante, settore specifico, fascia di prezzo). Contenuti che affrontano il soggetto per profili diversi o includono una sezione “a chi si rivolge” aumentano la copertura.
- Intento valutativo. “X vale la pena?”, “pro e contro di X” — il sistema cerca contenuti che aiutano l’utente a prendere una decisione. Sezioni dedicate a vantaggi/svantaggi, casi d’uso ottimali e limitazioni rispondono a questo intento.
- Intento temporale. “X nel 2025”, “aggiornamenti recenti su X” — il sistema privilegia contenuti aggiornati. Una data di revisione visibile, una sezione “aggiornamenti” con timestamp e riferimenti a sviluppi recenti segnalano freschezza ai sistemi RAG.
La copertura sistematica di tutte e sei le categorie in un singolo contenuto — attraverso sezioni dedicate, FAQ e tabelle — è la tecnica più efficace per massimizzare la probabilità di essere citati su tutte le sotto-query del fan-out. La galassia semantica costruita intorno alla keyword principale, analizzata come concetto nel capitolo sull’orchestrazione dell’intenzione e delle query implicite, trova qui la sua implementazione strutturale concreta.
Come mappare il fan-out di una keyword: metodo pratico in 4 passi
Mappare il query fan-out di una keyword target è un processo sistematizzabile. Il metodo che segue produce una mappa completa delle sotto-query implicite da coprire nel contenuto.
Passo 1 — Query diretta sull’AI. Eseguire la query target su Google AI Mode e Perplexity. Osservare la struttura della risposta generata: ogni affermazione della risposta corrisponde a una sotto-query che il sistema ha eseguito. Elencare tutti i sotto-topic coperti nella risposta.
Passo 2 — People Also Ask e People Also Search. Le sezioni People Also Ask nella SERP di Google e i related searches in fondo alla pagina rappresentano le sotto-query latenti che Google ha già identificato per quella keyword. Ogni voce PAA è una sotto-query potenziale del fan-out.
Passo 3 — Scomposizione per categoria. Applicare le sei categorie di intento latente alla keyword target. Per ciascuna categoria, formulare la sotto-query corrispondente e verificare se il contenuto esistente la copre. Le lacune identificate sono le priorità di integrazione.
Passo 4 — Verifica con keyword tool semantici. Strumenti come Semrush (keyword clustering), Answer the Public (domande implicite) e Google Search Console (query reali che generano impressioni) completano la mappa con dati empirici sul volume di ricerca delle sotto-query identificate.
| 📘 Il Manuale Completo della GEO
Stai leggendo il Capitolo 08 di 24 del Manuale AI Search di Instilla. Il metodo completo per mappare il fan-out e costruire la galassia semantica è sviluppato nei capitoli operativi della Parte III. Accedi al Manuale completo → |
Aggregazione delle fonti: come il sistema combina i risultati delle sotto-query
Dopo che il sistema ha eseguito le sotto-query del fan-out, deve aggregare i risultati. Questo è un processo non banale: ogni sotto-query produce un insieme di chunk candidati, spesso sovrapposti, talvolta contraddittori, con gradi di rilevanza diversi per la risposta finale. Il processo di aggregazione ha tre fasi.
Deduplication. I chunk simili o identici provenienti da sotto-query diverse vengono identificati e consolidati. Se tre sotto-query producono lo stesso chunk come top result, quel chunk riceve un punteggio aggregato più alto. Per chi produce contenuti, questo significa che un chunk che risponde a più sotto-query contemporaneamente — trasversale a più categorie di intento — ha un vantaggio strutturale nell’aggregazione.
Contradiction resolution. Il sistema identifica affermazioni contraddittorie tra fonti diverse. In genere, vengono privilegiate: fonti con E-E-A-T più alto, fonti più recenti, e affermazioni corroborate da più fonti indipendenti. Contenuti con affermazioni coerenti con il consenso delle fonti autorevoli vengono aggregati con minori penalità.
Synthesis ordering. Il modello decide l’ordine in cui presentare le informazioni aggregate nella risposta finale. L’intento principale della query viene sviluppato per primo; gli intenti latenti vengono integrati in ordine di rilevanza percepita. Un contenuto che risponde all’intento principale in modo eccellente tende a ricevere la prima citazione — il peso più alto nella risposta sintetica.
Strutturare il contenuto per il fan-out: la tecnica della galassia semantica
La tecnica della galassia semantica è l’approccio strutturale che permette a un singolo contenuto di coprire sistematicamente tutte le sotto-query del fan-out di una keyword. Il contenuto è organizzato come un sistema solare: un nucleo centrale (la risposta all’intento principale) circondato da sezioni satellite che rispondono ciascuna a un intento latente specifico.
La struttura concreta: nucleo (200-300 parole) — definizione, risposta diretta all’intento principale, TL;DR. Satelliti tematici (80-150 parole ciascuno) — una sezione per ogni categoria di intento latente identificata: definitoria, comparativa, procedurale, contestuale, valutativa, temporale. FAQ (60-100 parole per risposta) — 6-8 domande che coprono le sotto-query implicite non già sviluppate nelle sezioni. Tabelle e grafici — riepilogo visivo per le dimensioni comparative e valutative.
Il vantaggio di questa struttura non è solo la copertura del fan-out — è la riusabilità del contenuto: ogni sezione è un chunk autonomo che può emergere indipendentemente nelle risposte AI per la sotto-query corrispondente. Un contenuto con struttura a galassia semantica compare potenzialmente in 5-8 contesti di query diversi invece di uno solo. Questo è il moltiplicatore di visibilità che distingue i contenuti GEO-native dai contenuti SEO-native.
Esempi di fan-out per settore: mappatura pratica di intenti latenti
La tabella seguente mostra come il query fan-out si applica in tre settori diversi, con le sotto-query tipiche generate per una keyword rappresentativa.
| Settore / Keyword | Query principale | Sotto-query fan-out tipiche (5-7) |
| B2B SaaS”software gestione HR PMI” | Qual è il miglior software HR per PMI? | • Confronto software HR: X vs Y vs Z• Costo software HR PMI fascia media• Funzionalità base vs premium HR tool• Integrazione software HR con payroll• Tempi di implementazione HR software• Software HR con GDPR compliance italiana |
| Ecommerce”scarpe running uomo” | Quali scarpe da running scegliere? | • Differenza scarpe running asfalto vs trail• Scarpe running per pronatori vs supinatori• Miglior rapporto qualità-prezzo running 2025• Scarpe running per principianti vs avanzati• Come scegliere taglia scarpe running online• Marche scarpe running più affidabili |
| Finanza”ETF obbligazionario 2025″ | Come investire in ETF obbligazionari? | • ETF obbligazionario vs BTP: differenze• ETF obbligazionario rischi e rendimenti• Migliori ETF obbligazionari 2025 Europa• ETF obbligazionario a breve vs lungo termine• Fiscalità ETF obbligazionari in Italia• Come comprare ETF obbligazionari online |
Implicazioni per la content strategy: dal singolo articolo al cluster semantico
La comprensione del query fan-out ha una conseguenza strutturale sulla content strategy: il singolo articolo ottimizzato non è più l’unità di base della visibilità AI. L’unità di base è il cluster semantico — un insieme di contenuti correlati che coprono collettivamente tutte le sotto-query del fan-out di una keyword strategica.
Un cluster semantico efficace ha tre livelli: un contenuto pillar (1500-3000 parole) che copre il nucleo e i principali satelliti tematici, un insieme di contenuti satellite (500-800 parole ciascuno) che approfondiscono ogni sotto-query in modo autonomo, e una struttura di linking interno che collega il pillar ai satelliti con anchor descrittivi del contenuto di destinazione. Il sistema AI, durante il retrieval, vede il cluster come un’entità coerente — ogni satellite aumenta il segnale di topical authority dell’intero dominio su quella keyword.
La strategia di cluster semantici è il framework operativo sviluppato nel dettaglio nel capitolo dedicato alla content strategy progettata per la scoperta AI-native. Il presente capitolo fornisce la base teorica — il meccanismo del fan-out — che giustifica la struttura di quel framework.
| 🗺️ Mappa il fan-out delle tue keyword strategiche
Quante sotto-query del fan-out stai già coprendo? Il GEO Rank Simulator di Instilla analizza la copertura semantica dei tuoi contenuti rispetto al fan-out delle tue keyword target e identifica i gap di intento latente. Prova il Rank Simulator gratuitamente → |
Domande frequenti sul query fan-out
Cos’è il query fan-out nell’AI Search?
Il query fan-out è il processo attraverso cui un sistema AI Search scompone una query utente in un insieme di sotto-query atomiche che coprono l’intento latente — le domande che l’utente non ha scritto ma sta implicitamente cercando di rispondere. Ogni sotto-query viene eseguita separatamente sull’indice; i risultati vengono aggregati e sintetizzati nella risposta finale. Il numero di sotto-query generate varia da 2-3 per query semplici a 8-12 per query complesse. Per chi produce contenuti, il fan-out significa che coprire le sotto-query implicite di una keyword — non solo la query principale — moltiplica la probabilità di citazione.
Come si identifica l’intento latente di una keyword?
L’intento latente si identifica con un metodo in 4 passi: (1) query diretta sull’AI — osservare la struttura della risposta di Google AI Mode o Perplexity; ogni sotto-topic della risposta è una sotto-query del fan-out; (2) People Also Ask e related searches nella SERP di Google — ogni voce è una sotto-query latente documentata; (3) scomposizione per categoria — applicare le sei categorie di intento latente (definitorio, comparativo, procedurale, contestuale, valutativo, temporale) alla keyword target; (4) keyword tool semantici — Semrush, Answer the Public, Search Console per validare con dati di volume reale.
Cosa si intende per galassia semantica di un contenuto?
La galassia semantica è la struttura di contenuto che copre sistematicamente tutte le sotto-query del fan-out di una keyword. È organizzata come un sistema solare: un nucleo centrale (definizione + risposta all’intento principale, 200-300 parole) circondato da sezioni satellite (80-150 parole ciascuna) che rispondono a ogni categoria di intento latente. La galassia semantica non è solo un articolo lungo — è un articolo strutturalmente orientato alla copertura di ogni dimensione del fan-out, con FAQ che coprono le sotto-query residue e tabelle che sintetizzano le dimensioni comparative e valutative.
Qual è la differenza tra query fan-out e keyword clustering?
Il keyword clustering SEO tradizionale raggruppa keyword per similarità lessicale o semantica per strutturare il piano editoriale. Il query fan-out è un processo operativo del sistema AI Search — la scomposizione automatica di una singola query in sotto-query multiple al momento dell’interrogazione. I due concetti si intersecano: un buon keyword cluster corrisponde alle sotto-query del fan-out di una keyword strategica. La differenza pratica è che il fan-out rivela le sotto-query che il sistema genera autonomamente, non quelle che l’utente esplicita — offrendo insight più profondi sull’intento latente da coprire.
Un singolo articolo può coprire tutto il fan-out o serve un cluster?
Dipende dalla complessità dell’intento. Per keyword con fan-out semplice (2-4 sotto-query), un singolo articolo ben strutturato con le sezioni appropriate può coprire l’intero fan-out. Per keyword con fan-out complesso (6-12 sotto-query), la soluzione ottimale è un cluster semantico: un contenuto pillar che copre il nucleo e i satelliti principali, affiancato da contenuti satellite autonomi per le sotto-query più approfondite. Il cluster aumenta la topical authority del dominio su quella keyword — un segnale che tutte le piattaforme AI Search valutano positivamente nell’aggregazione delle fonti.
Come si misura se un contenuto copre correttamente il fan-out?
La verifica si esegue in due modi: qualitativo — per ogni sotto-query del fan-out identificata, eseguire manualmente la query su Google AI Mode e Perplexity e verificare se il proprio contenuto viene citato; quantitativo — monitorare le impressioni in Google Search Console per le keyword semanticamente correlate alla keyword target: se il contenuto riceve impressioni su molte varianti della keyword, copre bene le sotto-query del fan-out. Il framework di misurazione GEO nel Capitolo 12 include un metodo sistematico per il monitoraggio della copertura del fan-out.
Appendice A — Motivazione dei link interni
| Anchor → Destinazione | Motivazione |
| «come le keyword evolvono verso l’orchestrazione dell’intenzione» → Cap. 03 | Inserito nell’apertura: il fan-out è l’implementazione tecnica del concetto di orchestrazione dell’intenzione introdotto in Cap. 03. Link di back-reference che rafforza la coerenza della Parte I del Manuale. |
| «orchestrazione dell’intenzione e delle query implicite» → Cap. 03 (sezione S2) | Seconda citazione a Cap. 03 nella sezione sulle categorie di intento latente. Anchor variato — focus sulle query implicite — coerente con il contesto della sezione. |
| «content strategy progettata per la scoperta AI-native» → Cap. 11 | Nella sezione sul cluster semantico: il lettore che ha capito il fan-out è pronto per la strategia di contenuto operativa. Link verso Cap. 11 che anticipa la Parte III del Manuale. |
| «framework di misurazione GEO» → Cap. 12 (in FAQ) | Nella FAQ sulla misurazione della copertura del fan-out: risposta naturale alla domanda “come verifico?” con rimando al capitolo di misurazione. Crea ponti tra dimensione tecnica e analitica. |
Appendice B — Fonti citate
| # | Autore / Fonte | Titolo / Link | Anno |
| [1] | Aggarwal et al. — arXiv | GEO: Generative Engine Optimization (arXiv:2308.07525) | 2023 |
| [2] | Google Search Central | How Google Search Organizes Information — Query Understanding | 2024 |
| [3] | Answer the Public / NP Digital | Understanding Search Intent and Implicit Questions | 2024 |
| [4] | Semrush Research | Keyword Clustering and Topical Authority: Methodology Guide | 2024 |