Perché la query “rimedi contro l’insonnia” e la query “come dormire meglio la notte” producono risultati quasi identici su Google AI Mode ma risultati molto diversi su un motore di ricerca del 2005? La risposta non è nella qualità dell’algoritmo — è nel modello di rappresentazione del linguaggio che il sistema usa per capire cosa sta cercando l’utente. E comprendere questo modello è la premessa necessaria per capire perché alcuni contenuti vengono citati dall’AI e altri no.
Fino a pochi anni fa, la risposta alla domanda “come fa un motore di ricerca a trovare documenti rilevanti?” era relativamente semplice: conta le parole. Un documento che contiene più volte la parola cercata, in posizioni rilevanti (titolo, primo paragrafo, intestazioni), è probabilmente più rilevante di uno che la contiene meno. Questo sistema — noto come BM25 nella sua forma più sofisticata — ha alimentato la ricerca sul web per trent’anni. Funziona ancora, ed è ancora parte di quasi tutti i sistemi di retrieval moderni.
Ma non basta più. I sistemi AI Search hanno aggiunto un secondo strato — la ricerca neurale — che opera su una rappresentazione completamente diversa del testo. Capire come funziona questo strato, senza addentrarsi nella matematica dei transformer, è ciò che questo capitolo si propone di fare. È una conoscenza tecnica con conseguenze pratiche dirette: determina come strutturare i contenuti per massimizzare la probabilità di essere recuperati e citati.
Come funziona il recupero lessicale: BM25 e i suoi limiti
Il BM25 (Best Match 25) è l’algoritmo di ranking lessicale dominante dal 1994. Il principio è intuitivo: un documento è rilevante per una query se contiene le parole della query, e la rilevanza aumenta con la frequenza delle parole — ma in modo attenuato, per evitare che un documento che ripete “mutuo” cinquanta volte scali artificialmente il ranking. Due fattori principali modulano il punteggio: la frequenza del termine nel documento (più volte compare, più è rilevante) e la rarità del termine nel corpus (termini rari valgono di più di termini comuni come “il” o “di”).
Il risultato pratico: con BM25, per posizionarsi su “assicurazione auto giovani”, serve un documento che contenga esattamente quelle parole, in posizioni rilevanti, con frequenza sufficiente. Una pagina che tratta lo stesso argomento usando “polizza veicoli under 26” o “copertura RC auto neopatentati” è considerata irrilevante per quella query — anche se risponde perfettamente alla stessa necessità informativa.
Questo limite ha guidato trent’anni di keyword stuffing e ottimizzazione artificiale: ripeti le parole giuste nel posto giusto, e il sistema ti premia. Google ha combattuto questo fenomeno con layer aggiuntivi — PageRank, Panda, Penguin, BERT — ma il cuore lessicale del retrieval è rimasto. Fino all’avvento della ricerca neurale.
Cosa sono gli embedding: rappresentare il significato come vettore
Per capire la ricerca neurale, bisogna capire cosa sono gli embedding. Un embedding è una rappresentazione numerica di un testo — parola, frase, paragrafo o documento — in uno spazio vettoriale ad alta dimensionalità. In termini semplici: ogni testo viene trasformato in una lista di numeri (tipicamente tra 768 e 4096 valori) che catturano il suo significato in relazione a tutti gli altri testi nel corpus su cui il modello è stato addestrato.
La proprietà cruciale degli embedding è che testi con significato simile producono vettori vicini nello spazio numerico — anche se usano parole completamente diverse. L’embedding di “rimedi contro l’insonnia” e l’embedding di “come dormire meglio la notte” sono numericamente vicini perché i modelli di linguaggio hanno appreso, da miliardi di testi, che questi concetti compaiono in contesti simili e rispondono a bisogni simili. La vicinanza vettoriale è una misura di prossimità semantica, non di sovrapposizione lessicale.
Questa tecnologia — sviluppata attraverso architetture come Word2Vec (2013), BERT (2018) e i modelli Transformer successivi — ha reso possibile per i sistemi AI di capire che “cane” e “animale domestico a quattro zampe” parlano della stessa cosa, che “CEO” e “amministratore delegato” sono equivalenti, che “economico” e “a buon prezzo” coprono lo stesso intent. È il salto dal matching di parole al matching di significati.
Vector search: come la ricerca neurale trova i contenuti rilevanti
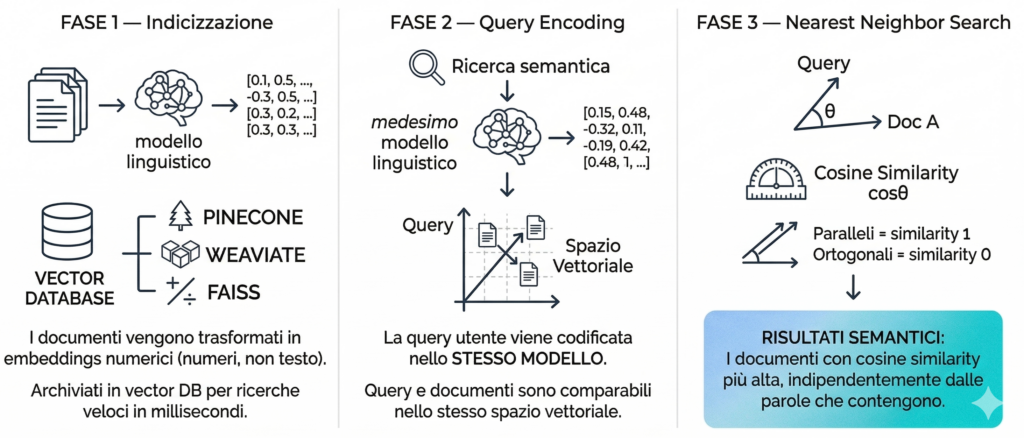
La vector search (o ricerca vettoriale) usa gli embedding per trovare documenti rilevanti con un meccanismo completamente diverso dal matching lessicale. Il processo ha tre fasi:
Fase 1 — Indicizzazione. Ogni documento nel corpus viene trasformato in un embedding dal modello e archiviato in un vector database. Non si archivia il testo — si archiviano i numeri che rappresentano il significato del testo. Sistemi come Pinecone, Weaviate o FAISS sono progettati specificamente per archiviare e interrogare miliardi di vettori in millisecondi.
Fase 2 — Query encoding. Quando l’utente invia una query, il sistema la trasforma in un embedding usando lo stesso modello usato per indicizzare i documenti. Ora sia la query che i documenti esistono nello stesso spazio vettoriale — sono comparabili.
Fase 3 — Nearest neighbor search. Il sistema trova i documenti il cui vettore è matematicamente più vicino al vettore della query — i nearest neighbors nello spazio semantico. La metrica più comune è la cosine similarity: misura l’angolo tra due vettori (due vettori paralleli hanno similarità 1; due vettori ortogonali hanno similarità 0). I documenti con cosine similarity più alta alla query sono i più rilevanti — indipendentemente dalle parole che contengono.
Il risultato pratico di questo meccanismo è che un documento può essere recuperato per una query anche se non contiene nessuna delle parole della query, purché il suo significato semantico sia vicino a quello della query. Questo è il motivo per cui la densità semantica — la copertura di un concetto attraverso molti termini correlati e contesti diversi — è più importante della densità di keyword nell’ottimizzazione per AI Search.
Ricerca ibrida: perché i sistemi moderni combinano BM25 e vector search
La ricerca neurale non ha soppiantato la ricerca lessicale — l’ha affiancata. I sistemi di retrieval moderni usano quasi sempre una ricerca ibrida: una combinazione di BM25 e vector search i cui punteggi vengono fusi (attraverso algoritmi come RRF, Reciprocal Rank Fusion) per produrre un ranking finale. La ragione è che i due sistemi hanno punti di forza complementari.
La ricerca lessicale eccelle nel recupero di termini esatti e tecnici: nomi propri, codici prodotto, terminologia specialistica, acronimi. Se un utente cerca “iPhone 15 Pro Max schermo rotto assistenza”, vuole risultati che contengano esattamente quelle parole — la vicinanza semantica a “smartphone danneggiato supporto tecnico” non è sufficiente. La ricerca neurale eccelle nel recupero di concetti espressi in modi diversi, nella comprensione dell’intent implicito, nella gestione di sinonimi e varianti linguistiche. I sistemi più sofisticati usano la ricerca lessicale come filtro iniziale per ridurre il corpus, poi applicano la ricerca neurale per il ranking finale — un approccio noto come retrieval a due stadi.
Secondo ricerche di Elasticsearch e della comunità IR open source[2], la ricerca ibrida supera sia BM25 che vector search standalone su benchmark standard di rilevanza, con guadagni medi di 15-25% sul NDCG@10 (Normalized Discounted Cumulative Gain, la metrica standard per la qualità del ranking). La combinazione non è un compromesso — è miglioramento.
| 📘 Il Manuale Completo della GEO
Stai leggendo il Capitolo 06 di 24 del Manuale AI Search di Instilla. L’analisi completa dei sistemi di retrieval AI, con le implicazioni pratiche per la struttura del contenuto e la strategia GEO, è sviluppata capitolo per capitolo. Accedi al Manuale completo → |
Il ruolo del reranking: come i sistemi AI scelgono cosa citare tra i risultati recuperati
Il retrieval — il recupero dei documenti candidati — è solo il primo passo. Dopo aver identificato un insieme di documenti potenzialmente rilevanti, i sistemi RAG applicano un secondo processo: il reranking. Il reranker è un modello separato — più preciso e più costoso computazionalmente del retriever — che analizza ogni documento candidato in relazione alla query specifica e assegna un nuovo punteggio di rilevanza.
I reranker moderni — come i modelli cross-encoder — non analizzano query e documento separatamente: li analizzano insieme, permettendo al modello di capire esattamente come e dove il documento risponde alla query. Questo permette una valutazione molto più fine: un reranker può riconoscere che un documento risponde alla query nel terzo paragrafo ma non nel primo, e pesare di conseguenza la rilevanza complessiva.
Per chi produce contenuti, il reranking ha un’implicazione diretta: la posizione della risposta nel documento conta. Un chunk che risponde alla micro-query nei primi due periodi ha una probabilità di sopravvivere al reranking superiore a un chunk che arriva alla risposta dopo tre paragrafi di contesto. La regola pratica è answer-first: la risposta alla domanda implicita di ogni sezione deve essere nel primo paragrafo della sezione, non al termine di un ragionamento progressivo.
Dal retrieval alla sintesi: come il modello costruisce la risposta finale
Una volta che il sistema RAG ha recuperato e reranked i documenti candidati, il modello linguistico (LLM) riceve questi documenti come contesto e genera la risposta finale. Questo è il momento in cui i contenuti smettono di essere recuperati e cominciano a essere sintetizzati: il modello non copia il testo — lo rielabora, lo integra con altri documenti, lo adatta alla query specifica dell’utente.
Il meccanismo di sintesi ha tre implicazioni pratiche per chi vuole essere citato:
- La citabilità di una affermazione dipende dalla sua chiarezza e dalla sua autonomia semantica. Un’affermazione ambigua che richiede il contesto del paragrafo precedente per essere compresa verrà parafrasata male o ignorata. Un’affermazione precisa, con soggetto esplicito e predicato chiaro, viene sintetizzata con fedeltà.
- La preferenza per il concreto sul generico. I modelli di sintesi tendono a selezionare affermazioni con dati specifici, esempi concreti e definizioni precise rispetto ad affermazioni generiche. “Il 67% degli utenti abbandona un sito in meno di 3 secondi se il caricamento è lento” è più citabile di “un sito lento perde visitatori” — anche se entrambe le affermazioni sono vere.
- La coerenza tra chunk e risposta sintetica. Il modello privilegia fonti i cui chunk sono internamente coerenti — non contraddittorie tra sezioni, non ambigue nelle definizioni. Un documento che definisce un termine in modo diverso in sezioni diverse produce una sintesi confusa e viene deprioritizzato nei retrieval successivi.
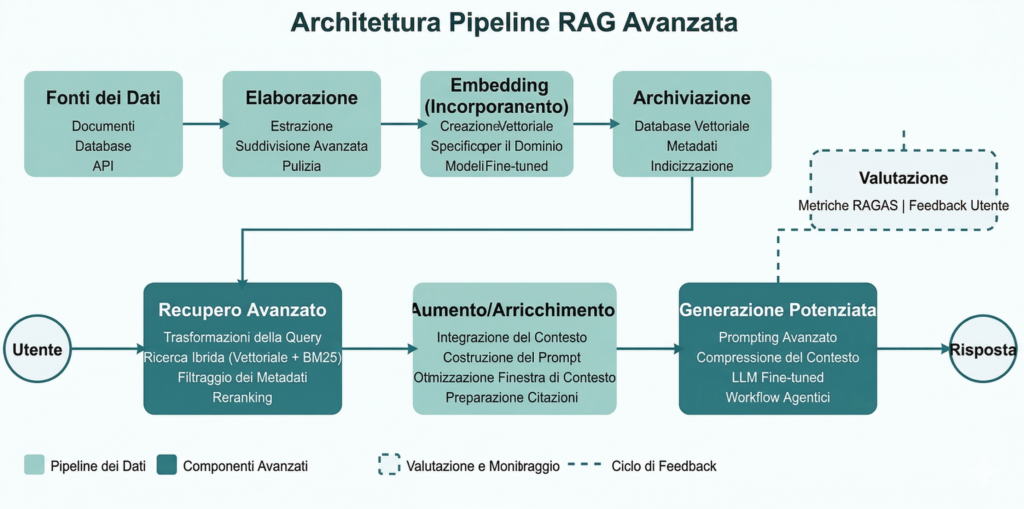
Implicazioni pratiche per la GEO: cosa cambia sapendo come funziona il retrieval
La comprensione del meccanismo di information retrieval neurale non è un’esercitazione teorica — trasforma il modo in cui si progettano i contenuti. Cinque principi pratici derivano direttamente dall’architettura dei sistemi RAG.
Principio 1 — Densità semantica, non densità di keyword. L’obiettivo non è ripetere la keyword target, ma costruire un campo semantico denso intorno al concetto. Sinonimi, termini correlati, esempi d’uso, definizioni di termini adiacenti — tutto contribuisce all’embedding del documento e avvicina il suo vettore alle query target. Un testo che usa “insonnia”, “qualità del sonno”, “ciclo circadiano”, “igiene del sonno” e “latenza dell’addormentamento” produce un embedding più ricco — e più citabile — di un testo che ripete “insonnia” dieci volte.
Principio 2 — Chunk semanticamente autonomi. Il retrieval opera su chunk, non su interi documenti. Ogni chunk deve avere un embedding autonomo che rappresenti il suo significato senza dipendere dal contesto circostante. Questo significa: soggetti espliciti (no pronomi anaforici), definizioni di termini tecnici la prima volta che compaiono nel chunk, risposta alla micro-domanda nei primi due periodi.
Principio 3 — Answer-first, context-second. Il reranking privilegia chunk che rispondono alla query nelle prime righe. La struttura answer-first — risposta immediata seguita dal contesto esplicativo — è più compatibile con i sistemi RAG della struttura context-first tipica del giornalismo narrativo (problema, storia, soluzione). Per i contenuti ottimizzati AI, scrivere come un reference manual, non come un articolo di rivista.
Principio 4 — Specificità e dati verificabili. Il modello di sintesi privilegia affermazioni specifiche su affermazioni generiche. Ogni claim importante dovrebbe essere accompagnato da un dato quantitativo, un esempio concreto o una fonte verificabile. Non solo rende il contenuto più citabile — aumenta il punteggio di trustworthiness che i sistemi RAG assegnano alle fonti.
Principio 5 — Coerenza terminologica intra-documento. Usare lo stesso termine per lo stesso concetto in tutto il documento. Il modello costruisce l’embedding del chunk parzialmente in base al contesto degli altri chunk dello stesso documento: incoerenze terminologiche producono un embedding meno preciso e un reranking più basso.
Come questi principi si traducono in architettura concreta del contenuto — struttura delle sezioni, lunghezza dei chunk, uso delle intestazioni — è il tema del capitolo dedicato a come i motori AI analizzano tecnicamente ogni piattaforma leader e, più in dettaglio, del capitolo sul cuore tecnico della GEO applicato alla struttura del contenuto.
| 🔬 Verifica la densità semantica del tuo contenuto
Il tuo contenuto è ottimizzato per il retrieval neurale o solo per la ricerca lessicale? Il GEO Rank Simulator di Instilla analizza la densità semantica dei tuoi contenuti principali e identifica i gap rispetto ai documenti citati dai sistemi AI per le tue query target. Prova il Rank Simulator gratuitamente → |
Confronto: ricerca lessicale vs ricerca neurale vs ricerca ibrida
La tabella seguente sintetizza le differenze operative tra i tre approcci di retrieval, con indicazione delle implicazioni pratiche per chi ottimizza contenuti.
| Dimensione | Lessicale (BM25) | Neurale (Vector Search) | Ibrida (BM25 + Vector) |
| Meccanismo | Match parole esatte + frequenza termine | Similarità vettoriale nello spazio semantico | Fusione punteggi BM25 + cosine similarity |
| Forza principale | Termini tecnici esatti, nomi propri, codici | Sinonimi, intent implicito, varianti linguistiche | Copertura completa: esatto + concettuale |
| Debolezza | Cieco a sinonimi e parafrasie | Meno preciso su termini rari e tecnici | Complessità computazionale maggiore |
| Cosa ottimizzare | Keyword density, posizione nel testo, intestazioni | Densità semantica, copertura concettuale, chunk quality | Entrambe le dimensioni contemporaneamente |
| Metrica di successo | Posizione SERP per keyword target | Cosine similarity media con query target | NDCG@10, citation rate nelle risposte AI |
| Usato da | Google (1998-2018), Bing tradizionale | Sistemi RAG puri, alcuni vector DB | Google AI Mode, Perplexity, ChatGPT Search, Bing Copilot |
Confronto tra i tre paradigmi di information retrieval: lessicale, neurale e ibrido. Implicazioni per la strategia di ottimizzazione contenuti. Elaborazione Instilla, 2025.
Domande frequenti sull’information retrieval AI
Cos’è il BM25 e perché è ancora rilevante nell’AI Search?
Il BM25 (Best Match 25) è l’algoritmo di ranking lessicale dominante dal 1994. Il meccanismo è basato sulla frequenza dei termini: un documento è rilevante per una query se contiene le parole della query, con punteggio proporzionale alla frequenza e inversamente proporzionale alla rarità del termine nel corpus. È ancora rilevante perché i sistemi AI Search moderni usano ricerca ibrida: BM25 per il recupero di termini tecnici esatti, nomi propri e codici prodotto; ricerca neurale per la comprensione dell’intent implicito. La combinazione dei due approcci supera entrambi i sistemi standalone del 15-25% sulle metriche di rilevanza standard.
Cosa sono gli embedding e come influenzano la visibilità nei motori AI?
Un embedding è una rappresentazione numerica di un testo — parola, frase, paragrafo o documento — in uno spazio vettoriale ad alta dimensionalità. Testi con significato simile producono vettori numericamente vicini, indipendentemente dalle parole usate. Questo significa che un documento ottimizzato per la densità semantica — che copre un concetto attraverso molti termini correlati, sinonimi, esempi e contesti — ha un embedding più ricco e una probabilità di recupero più alta rispetto a un documento che ripete la stessa keyword. Per la visibilità nei motori AI, costruire densità semantica è più efficace che ottimizzare la keyword density.
Cos’è la vector search e come funziona?
La vector search è il meccanismo di retrieval usato dai sistemi AI per trovare documenti semanticamente rilevanti. Funziona in tre fasi: (1) indicizzazione — ogni documento viene trasformato in un vettore numerico (embedding) e archiviato in un vector database; (2) query encoding — la query dell’utente viene trasformata nello stesso spazio vettoriale; (3) nearest neighbor search — il sistema trova i documenti il cui vettore è matematicamente più vicino alla query, usando la cosine similarity come metrica. I documenti più vicini — semanticamente, non lessicalmente — vengono recuperati come candidati per la risposta AI.
Cos’è il reranking e perché cambia l’ordine dei risultati dopo il retrieval?
Il reranking è il secondo stadio del processo RAG: dopo che il retrieval ha identificato un insieme di documenti candidati, un modello cross-encoder analizza ogni documento in relazione alla query specifica e assegna un nuovo punteggio di rilevanza. A differenza del retriever — che analizza query e documenti separatamente — il reranker li analizza insieme, permettendo una valutazione più fine. L’implicazione pratica: i chunk che rispondono alla query nelle prime righe (struttura answer-first) sopravvivono meglio al reranking rispetto ai chunk che arrivano alla risposta dopo paragrafi di contesto.
Devo ancora ottimizzare le keyword se i sistemi AI usano embedding semantici?
Sì, ma l’ottimizzazione delle keyword va integrata con la densità semantica. I sistemi AI moderni usano ricerca ibrida: BM25 per i termini esatti (ancora rilevante per query tecnici, nomi propri, prodotti specifici) e vector search per l’intent concettuale. La keyword principale deve comparire in posizioni chiave — titolo, primo paragrafo, intestazioni — perché BM25 continua a contribuire al ranking. Ma la frequenza della keyword è meno importante della copertura semantica del concetto: sinonimi, termini correlati, esempi d’uso, definizioni di termini adiacenti costruiscono un embedding più ricco e aumentano la probabilità di essere recuperati per tutta la galassia di micro-intent correlati alla keyword.
Come si costruisce un chunk ottimizzato per il retrieval neurale?
Un chunk ottimizzato per il retrieval neurale ha quattro caratteristiche: (1) autonomia semantica — risponde a una micro-domanda specifica senza richiedere il contesto degli altri chunk; (2) answer-first — la risposta è nelle prime due frasi, il contesto esplicativo segue; (3) densità semantica — usa termini correlati e sinonimi del concetto target, non solo la keyword principale; (4) specificità — include almeno un dato quantitativo, un esempio concreto o una definizione precisa. La dimensione ottimale per il retrieval RAG è tra 80 e 200 parole: abbastanza lungo da avere un embedding semanticamente ricco, abbastanza corto da essere estratto senza perdere contesto rilevante.
Appendice A — Motivazione dei link interni
Ogni link interno è documentato con la motivazione editoriale e GEO che giustifica il collegamento.
| Anchor → Destinazione | Motivazione |
| «come i motori AI analizzano tecnicamente ogni piattaforma leader» → Cap. 07 | Inserito nella sezione sulle implicazioni pratiche GEO: il lettore che ha capito i principi del retrieval è pronto per l’analisi tecnica delle singole piattaforme. Link funzionale che anticipa il capitolo successivo, creando continuità narrativa nella Parte II del Manuale. |
| «cuore tecnico della GEO applicato alla struttura del contenuto» → Cap. 09 | Posizionato nella stessa sezione delle implicazioni pratiche, come secondo link verso la Parte III: chi ha assimilato la teoria del retrieval vuole il framework operativo. Anchor diverso da altri riferimenti a Cap. 09 — focus sulla struttura del contenuto, coerente con il contesto tecnico del capitolo. |
Appendice B — Fonti citate
| ℹ️ Nota metodologica sulle citazioni
Le fonti citate includono letteratura accademica fondamentale, documentazione tecnica ufficiale e benchmark di community open source. Il paper originale BM25 [1] è di Robertson e Zaragoza (2009) — una raccolta sistematica del lavoro originale degli anni ’90. Il benchmark Elasticsearch/BEIR [2] è il riferimento standard per la comparazione di sistemi di retrieval. Il paper BERT [3] di Devlin et al. (2018) è la fonte primaria per la tecnologia di embedding contestuale. Il paper ‘Attention Is All You Need’ [4] di Vaswani et al. (2017) è il paper seminale sull’architettura Transformer. |
| # | Autore / Fonte | Titolo / Link | Anno |
| [1] | Robertson, S. & Zaragoza, H. | The Probabilistic Relevance Framework: BM25 and Beyond | 2009 |
| [2] | Thakur et al. / Elasticsearch | BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of IR Models | 2021 |
| [3] | Devlin et al. — Google AI | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | 2018 |
| [4] | Vaswani et al. — Google Brain | Attention Is All You Need (Transformer Architecture) | 2017 |