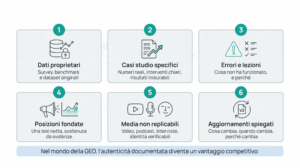
Le fonti che i motori generativi citano con più frequenza hanno una struttura in comune. Non è un caso: è il risultato di scelte architetturali deliberate, progettate per essere compatibili con i sistemi RAG.
La GEO è la disciplina che studia e sistematizza quelle scelte. Questo capitolo è il manuale operativo: ogni leva di ottimizzazione con specifiche tecniche, esempi before/after e checklist di implementazione.
Se stai valutando come applicare la GEO alla tua azienda, puoi esplorare i servizi GEO di Instilla.
Questo pattern non è coincidente — è il risultato di un’architettura di contenuto deliberatamente progettata per essere compatibile con i sistemi RAG. La GEO — Generative Engine Optimization — è precisamente la disciplina che studia e sistematizza queste scelte. Non si tratta di trucchi o scorciatoie: si tratta di capire come funzionano le pipeline RAG, come si è analizzato nei capitoli precedenti su information retrieval neurale e embedding e architettura tecnica delle singole piattaforme, e di costruire contenuti che eccellono in ogni fase di quel processo.
Questo capitolo è il manuale operativo: specifica tecnica di ogni leva di ottimizzazione, con esempi before/after, metriche di controllo e checklist di implementazione.
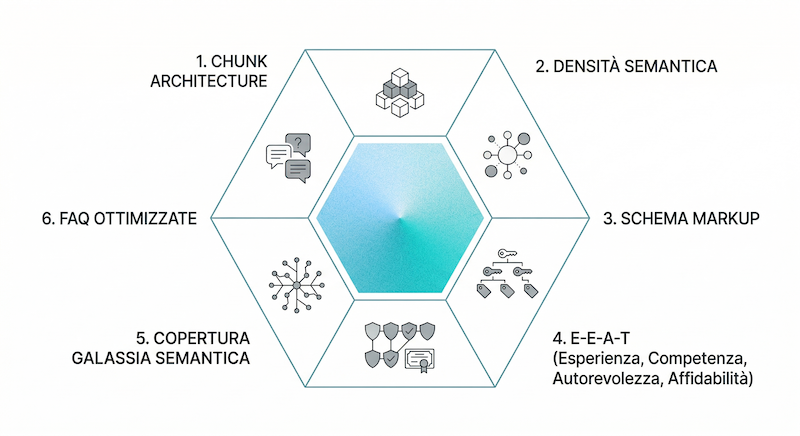
Leva 1 — Chunk Architecture: la struttura atomica del contenuto citabile
Il chunk è l’unità atomica del retrieval AI: la porzione di testo che il sistema RAG estrae dal documento per valutarla come risposta a una micro-query. La progettazione dei chunk è la leva più impattante nella GEO perché agisce direttamente sul retrieval — la fase che determina se il contenuto entra o meno nel pool dei candidati alla citazione.
Un chunk ottimizzato ha quattro caratteristiche strutturali. Autonomia semantica: risponde a una micro-domanda specifica senza richiedere il contesto dei chunk precedenti o successivi. Struttura answer-first: la risposta alla micro-domanda è nelle prime due frasi del chunk — il reranker privilegia i chunk che arrivano alla risposta subito, non dopo paragrafi di introduzione. Densità semantica: usa termini correlati al concetto target, non solo la keyword. Dimensione ottimale: tra 80 e 200 parole — abbastanza lungo da avere un embedding semanticamente ricco, abbastanza corto da essere estratto senza perdere coerenza.
Regola pratica: ogni sezione H2 è un chunk di primo livello. Ogni paragrafo all’interno della sezione è un chunk di secondo livello. Il titolo H2 deve essere la query che il chunk risponde — non una label descrittiva generica (“Caratteristiche del prodotto”) ma una domanda o un’affermazione che riflette la micro-query (“Quanto costa [prodotto] per una PMI con 10 utenti?”). Il primo paragrafo sotto l’H2 risponde direttamente a quella domanda.
| ⚖️ Esempio Before / After — Chunk Architecture
❌ PRIMA (chunk non ottimizzato): “In questa sezione analizziamo le principali funzionalità del nostro software gestionale, sviluppate nel corso di anni di ricerca e ascolto delle esigenze dei clienti. Il software è stato progettato con un approccio user-centric che mette al centro le necessità delle piccole e medie imprese italiane…” ✅ DOPO (chunk ottimizzato — answer-first): “Il software gestionale include 5 moduli core: fatturazione elettronica, magazzino, CRM, contabilità e reportistica. Ogni modulo è attivabile separatamente — una PMI con 10 dipendenti parte tipicamente da fatturazione + magazzino a €49/mese. I moduli si integrano nativamente con Google Workspace, Microsoft 365 e i principali e-commerce italiani (Shopify, WooCommerce, Prestashop).” |
Leva 2 — Densità Semantica: costruire il campo concettuale attorno alla keyword
La densità semantica è la misura di quanti termini correlati al concetto target sono presenti in un chunk. Un chunk con alta densità semantica produce un embedding più ricco — numericamente più vicino alle diverse varianti di query che gli utenti usano per cercare quel concetto. Come si è visto nel capitolo su come la ricerca neurale usa gli embedding per trovare contenuti rilevanti, la keyword density è una metrica obsoleta: quello che conta è la densità del campo semantico intorno al concetto.
Come costruire densità semantica in pratica: usare sinonimi espliciti nella stessa sezione (CRM, gestione clienti, customer relationship management, software commerciale); includere termini coordinate (concetti dello stesso livello di astrazione: CRM, ERP, software gestionale, piattaforma vendite); includere termini iponimi ed iperonimi (specifico e generico: Salesforce, HubSpot → CRM → software aziendale); includere collocazioni tipiche (frasi che co-occorrono naturalmente: “pipeline di vendita”, “gestione lead”, “tasso di conversione commerciale”).
Lo strumento più efficace per costruire densità semantica è l’analisi delle fonti già citate dai sistemi AI per le proprie query target: estrarre il vocabolario usato in quelle fonti e verificare quanti termini siano presenti nel proprio contenuto. I gap di vocabolario identificati sono le opportunità di ottimizzazione più dirette. Come si analizza nel capitolo sulla Generative Authority Strategy e la pratica della visibilità, la semantic gap analysis è il punto di partenza dell’ottimizzazione iterativa.
Leva 3 — Schema Markup: parlare la lingua delle macchine
Lo schema markup (structured data) è il sistema di annotazione semantica che rende il contenuto interpretabile a livello macchina — non solo per i motori di ricerca tradizionali ma per i sistemi RAG che usano il markup come segnale di struttura e autorità. I tre tipi di schema con impatto maggiore sulla citabilità AI sono:
- FAQPage: il tipo di schema con l’impatto più diretto sulla visibilità AI. Ogni elemento Question/Answer nello schema è un chunk auto-contenuto che il sistema RAG può estrarre direttamente. Un FAQPage con 5-7 domande ben formulate moltiplica il numero di micro-query per cui il contenuto è candidato alla citazione.
- Article / TechArticle: segnala al sistema la struttura editoriale del contenuto (titolo, autore, data di pubblicazione, data di aggiornamento, argomento). La dateModified è particolarmente importante per le sub-query temporali del fan-out — un contenuto con dateModified recente ha un vantaggio significativo rispetto a contenuti privi di questo segnale.
- HowTo: per contenuti procedurali, lo schema HowTo struttura esplicitamente ogni passo come chunk indipendente con titolo e descrizione. I sistemi RAG estraggono i passi HowTo come risposte dirette a query del tipo “come fare X” con alta precisione.
La regola di implementazione: il codice JSON-LD va inserito nell’<head> della pagina, non nel body. Il contenuto dello schema deve essere coerente con il contenuto visibile sulla pagina — un sistema RAG che trova discrepanze tra schema e contenuto assegna un punteggio di affidabilità più basso.
Leva 4 — E-E-A-T verificabile: costruire fiducia leggibile dalla macchina
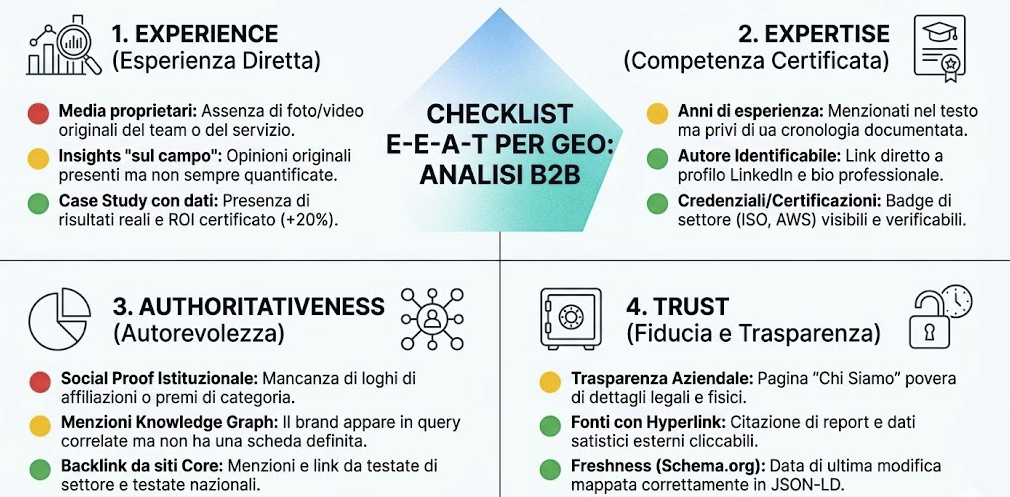
I segnali E-E-A-T (Experience, Expertise, Authoritativeness, Trust) non sono solo criteri qualitativi di valutazione editoriale — sono segnali che i sistemi RAG usano per pesare l’autorità della fonte nella fase di reranking. Un contenuto tecnicamente ottimizzato ma con E-E-A-T debole ha una probabilità di citazione inferiore a un contenuto meno ottimizzato tecnicamente ma con forte segnale di autorità.
I quattro segnali E-E-A-T con impatto più diretto sulla citabilità AI: autore identificabile con nome, ruolo e link al profilo professionale (LinkedIn, pagina autore del sito); credenziali verificabili dell’autore pertinenti all’argomento (specializzazioni, certificazioni, anni di esperienza documentati); fonti citate con hyperlink cliccabili — un contenuto che cita fonti esterne autorevoli ottiene un segnale di affidabilità più alto di uno che non cita nulla; data di aggiornamento visibile nel markup e nello schema — segnala freschezza e cura editoriale.
Per i siti B2B e professionali, un segnale E-E-A-T aggiuntivo di alto impatto è la prova sociale istituzionale: citazioni di case study con dati quantificati, menzioni in media di settore, affiliazioni professionali verificabili. Un sistema RAG che vede queste prove nel contenuto o nella pagina About del sito aumenta il punteggio di autorità del dominio per le query di settore.
Leva 5 — Copertura della Galassia Semantica: rispondere prima che l’utente chieda
La quinta leva integra l’analisi del query fan-out e dell’intento latente sviluppata nel capitolo precedente in una strategia di struttura del contenuto. L’obiettivo è costruire un documento che risponda non solo alla query principale ma alle sub-query principali che il fan-out genera — ciascuna con una sezione dedicata, auto-contenuta, ottimizzata come chunk indipendente.
La regola pratica: per ogni query target, identificare le 5-8 sub-query più probabili del fan-out (usando People Also Ask, ricerche correlate, analisi competitor). Per ognuna, verificare se il contenuto ha una sezione dedicata. Se la sezione manca, è un gap da colmare — con priorità proporzionale al volume di query della sub-query. Un documento che copre 8 delle 10 sub-query più frequenti ha una probabilità di citazione significativamente più alta di un documento che copre solo la query principale.
Un caso speciale: le sub-query comparative (“X vs Y”, “alternativa a X”). I sistemi AI generano quasi sempre sub-query comparative per query con intent valutativo. Un contenuto che include una sezione “Confronto con le principali alternative” — con tabella comparativa imparziale — ha alta probabilità di essere citato per queste sub-query, anche da competitor che cercano alternative al tuo prodotto.
Leva 6 — FAQ Ottimizzate: il moltiplicatore di micro-query coperte
La sezione FAQ è il componente con il miglior rapporto effort/impatto nella GEO. Un blocco di 5-7 domande ben strutturate, con risposte auto-contenute e schema FAQPage, moltiplica il numero di micro-query per cui il contenuto è candidato alla citazione — potenzialmente raddoppiando la copertura della galassia semantica con un singolo elemento editoriale.
Le regole di ottimizzazione delle FAQ per la citabilità AI: ogni domanda deve essere formulata esattamente come un utente la digitherebbe in un motore AI — non come una domanda retorica o un titolo di sezione. La risposta deve essere auto-contenuta entro 100-150 parole, con la risposta principale nella prima frase. Ogni risposta FAQ deve includere la keyword della domanda nella risposta (per la componente BM25 del retrieval ibrido). Il blocco FAQ deve essere preceduto da un’intestazione “Domande frequenti” o equivalente che segnali la struttura al crawler.
Il numero ottimale di domande FAQ per la GEO è 5-7 per pagina: abbastanza da coprire le sub-query principali, non così tante da diluire l’autorità semantica di ogni singola risposta. Le domande devono essere calibrate sulla galassia semantica della pagina — domande diverse da quelle già coperte nelle sezioni H2 del corpo del testo, non ripetizioni degli stessi argomenti in formato domanda-risposta.
| 📘 Il Manuale Completo della GEO
Stai leggendo il Capitolo 09 di 24 del Manuale AI Search di Instilla. Le specifiche tecniche complete, le checklist di implementazione e i template operativi per ciascuna delle 6 leve sono disponibili nel Manuale completo. Accedi al Manuale completo → |
Matrice di priorità: 6 leve × impatto × effort
La tabella seguente organizza le sei leve GEO per impatto stimato sulla citation rate e per effort di implementazione, permettendo di definire la sequenza ottimale di intervento per un sito con risorse limitate.
| Leva GEO | Impatto citation rate | Effort | Priorità (1-6) | Prima azione concreta |
| Chunk Architecture | ★★★★★ Molto alto | Medio — richiede revisione struttura | 1 | Riscrivere le prime 3 sezioni H2 con struttura answer-first |
| FAQ Ottimizzate | ★★★★★ Molto alto | Basso — aggiunta incrementale | 2 | Aggiungere blocco FAQ con 5 domande + schema FAQPage JSON-LD |
| Schema Markup | ★★★★ Alto | Basso — tecnico puro | 3 | Implementare Article schema con dateModified + FAQPage |
| Densità Semantica | ★★★★ Alto | Medio — editing del testo | 4 | Arricchire vocabolario delle prime 3 sezioni con sinonimi e termini coordinati |
| Copertura Galassia | ★★★ Medio-alto | Alto — nuovi contenuti | 5 | Aggiungere 2-3 sezioni per sub-query PAA non coperte |
| E-E-A-T verificabile | ★★★ Medio-alto | Medio — aggiornamento profilo | 6 | Aggiungere pagina autore con credenziali + citazioni fonti nelle sezioni principali |
Matrice priorità delle 6 leve GEO: impatto stimato sulla citation rate, effort di implementazione e prima azione concreta. Elaborazione Instilla basata su Google SQRG 2025 e analisi di pattern di citazione AI.
| 🔧 Implementa le 6 leve sul tuo contenuto
Quali delle 6 leve GEO sono già implementate nel tuo contenuto e quali mancano? Il GEO Rank Simulator di Instilla valuta il tuo contenuto sulle 6 leve e produce un piano di implementazione prioritizzato con le azioni ad alto impatto da fare subito. Ottieni il tuo piano GEO → |
Domande frequenti sul cuore tecnico della GEO
Qual è la differenza tra SEO tradizionale e GEO?
La SEO tradizionale ottimizza per il posizionamento nei risultati organici di un motore di ricerca: il successo si misura in ranking e CTR. La GEO (Generative Engine Optimization) ottimizza per la citation rate nelle risposte generate dall’AI: il successo si misura nella frequenza con cui il sistema AI cita il tuo contenuto come fonte. Le due discipline condividono le fondamenta (indicizzazione, autorità del dominio, qualità del contenuto) ma divergono sulle tecniche specifiche: la GEO richiede struttura a chunk, densità semantica, schema markup e copertura della galassia semantica — elementi che il SEO tradizionale non ottimizzava sistematicamente.
Come si struttura un chunk ottimizzato per la GEO?
Un chunk ottimizzato ha quattro caratteristiche: (1) autonomia semantica — risponde a una micro-domanda specifica senza contesto esterno; (2) answer-first — la risposta è nelle prime due frasi; (3) densità semantica — usa sinonimi, termini correlati e collocazioni tipiche del concetto target, non solo la keyword; (4) dimensione 80-200 parole — abbastanza da avere embedding ricco, abbastanza corto da essere estratto senza perdita. Il titolo H2 che introduce il chunk deve essere formulato come la micro-query a cui il chunk risponde — non come label descrittiva generica.
Lo schema markup FAQPage aiuta davvero la visibilità nelle risposte AI?
Sì — è uno dei segnali con il miglior rapporto effort/impatto nella GEO. Ogni elemento Question/Answer nello schema FAQPage è un chunk auto-contenuto che il sistema RAG può estrarre direttamente, senza dover analizzare e segmentare il testo. Questo abbassa la soglia di retrieval per ogni domanda: il sistema non deve valutare se il paragrafo risponde alla query — lo schema lo dichiara esplicitamente. Un FAQPage con 5-7 domande ben formulate moltiplica il numero di micro-query per cui il contenuto è candidato alla citazione.
Quante parole deve avere un chunk per essere ottimale per il retrieval AI?
La dimensione ottimale per il retrieval RAG è tra 80 e 200 parole. Chunk troppo corti (meno di 50 parole) hanno embedding poco ricchi — il vettore cattura poca informazione semantica. Chunk troppo lunghi (oltre 300-400 parole) vengono troncati dal sistema durante il retrieval, con perdita di contesto rilevante. La fascia 80-200 parole ottimizza il bilanciamento tra ricchezza dell’embedding e precisione dell’estrazione. Per sezioni molto lunghe, la soluzione è strutturare in più paragrafi da 100-150 parole ciascuno, ognuno con un focus tematico distinto.
Come si misura la citation rate nelle risposte AI?
La citation rate — la frequenza con cui le risposte AI citano il tuo contenuto — si misura con un processo di monitoraggio sistematico: inviare periodicamente le query target alle piattaforme AI (Google AI Mode, Perplexity, ChatGPT Search) e registrare se e come il tuo dominio appare nelle fonti citate. Il sistema di monitoraggio richiede automazione per le query ad alto volume. Le metriche principali da tracciare sono: presenza nelle fonti (sì/no per ogni query), posizione nelle fonti (prima, seconda, terza fonte citata), tipo di citazione (inline vs nota finale). Il framework completo di misurazione è nel capitolo sul divario della misurazione nella GEO.
Appendice A — Motivazione dei link interni
| Anchor → Destinazione | Motivazione |
| «information retrieval neurale e embedding» → Cap. 06 | Inserito nell’apertura per ancorare il capitolo operativo alla teoria del retrieval. Il lettore che arriva a Cap. 09 conosce già il meccanismo — il link è un richiamo esplicito della base teorica su cui si costruisce la pratica GEO. |
| «architettura tecnica delle singole piattaforme» → Cap. 07 | Seconda citazione nell’apertura: insieme a Cap. 06 forma il binomio teoria (retrieval) + architettura (piattaforme) che costituisce le premesse della GEO operativa. Anchor diverso da altri riferimenti a Cap. 07 — focus sull’architettura delle singole piattaforme coerente con il contesto. |
| «come la ricerca neurale usa gli embedding» → Cap. 06 (seconda citazione) | Seconda citazione a Cap. 06 nella sezione sulla densità semantica. Anchor più specifico (embedding) coerente con il contesto tecnico dove si spiega il legame tra vocabolario e qualità del vettore. |
| «Generative Authority Strategy e la pratica della visibilità» → Cap. 10 | Inserito nella sezione sulla densità semantica come bridge verso il capitolo successivo: chi vuole implementare la semantic gap analysis trova il framework strategico in Cap. 10. |
| «query fan-out e dell’intento latente» → Cap. 08 | Inserito nella sezione sulla Copertura della Galassia Semantica: rimanda esplicitamente al capitolo che ha introdotto il concetto di fan-out. Link di continuità narrativa che rafforza la coerenza della Parte II del Manuale. |
| «divario della misurazione nella GEO» → Cap. 12 | Inserito nell’ultima FAQ sulla misurazione della citation rate. Link che chiude il loop: chi ha implementato le 6 leve vuole sapere come misurarle. Anticipa la Parte IV del Manuale. |
Appendice B — Fonti citate
| ℹ️ Nota metodologica sulle citazioni
Le fonti di questo capitolo includono le Google Search Quality Rater Guidelines (fonte primaria per E-E-A-T), ricerca accademica su GEO e pattern di citazione AI, e analisi di benchmark RAG. Il paper Aggarwal et al. [1] è il riferimento principale per i pattern di citazione nei sistemi RAG. Le Google SQRG [2] sono la fonte primaria per la definizione operativa di E-E-A-T. La ricerca Press et al. [3] documenta l’impatto dello schema markup sulla visibilità nei sistemi AI. Il paper Lewis et al. [4] è il paper fondamentale sul RAG (Retrieval-Augmented Generation). |
| # | Autore / Fonte | Titolo / Link | Anno |
| [1] | Aggarwal et al. | Generative Information Retrieval: A Survey of RAG in Production (arXiv 2308.07525) | 2023 |
| [2] | Google — Search Quality Team | Search Quality Rater Guidelines — January 2025 | 2025 |
| [3] | Press et al. / Hugging Face Research | GEO: Generative Engine Optimization (arXiv 2311.09735) | 2023 |
| [4] | Lewis et al. — Facebook AI Research | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks | 2020 |