Il problema dei dati grezzi: quando il citation rate inganna
Un’azienda che produce software per la gestione logistica monitora sistematicamente la propria visibilità generativa. I dati mostrano un citation rate dell”41% su un campione di 80 query. Il team è soddisfatto: più di 4 query su 10 producono una citazione del brand.
Poi analizzano il dettaglio. Le citazioni si concentrano quasi esclusivamente su query del tipo “software gestione magazzino” e “WMS per PMI”. Per le query ad alto valore commerciale — “integrazione logistica supply chain enterprise”, “ottimizzazione last mile delivery”, “3PL software per e-commerce” — il brand non compare mai.
Il citation rate aggregato era tecnicamente corretto ma strategicamente fuorviante. L’azienda era ben posizionata per un segmento di mercato che non rappresentava la propria priorità di business, e invisibile per i segmenti chiave. Senza attribuzione per intent, i dati di tracking diventano un’illusione di controllo.
Questo è il problema centrale che l’attribuzione di query ed entità risolve: trasformare un numero aggregato in una mappa strategica che mostra esattamente dove il brand è riconosciuto, dove non lo è, e dove esistono le maggiori opportunità di espansione.
Entità e knowledge graph: come i modelli organizzano la conoscenza
Per capire l’attribuzione, è necessario comprendere come i modelli linguistici organizzano le informazioni. A differenza dei motori di ricerca tradizionali, che indicizzano documenti, i LLM costruiscono reti di relazioni semantiche durante il training.
Al centro di questa struttura c’è il concetto di entità: un oggetto del mondo reale o concettuale con un’identità distinta. Un’azienda è un’entità. Un fondatore è un’entità. Un prodotto, un metodo, un settore industriale sono entità. I modelli apprendono le relazioni tra entità attraverso miliardi di testi — e queste relazioni formano una rete chiamata knowledge graph implicito.
Quando un utente chiede “qual è la migliore soluzione per la gestione del cold chain?”, il modello non cerca documenti: attiva una rete di associazioni tra l’entità “cold chain management” e le entità ad essa correlate: aziende specializzate, metodologie, tecnologie, certificazioni, casi studio. Il brand che compare nella risposta è quello per cui questa associazione è più forte nella rete interna del modello.
L’implicazione pratica è fondamentale: la visibilità generativa dipende dalla forza delle associazioni semantiche tra il proprio brand e i topic rilevanti, non semplicemente dalla presenza di contenuti su quei topic. Due aziende con la stessa quantità di contenuti su un argomento possono avere associazioni semantiche molto diverse nei modelli.
Entity mapping: identificare le entità del proprio brand
Il primo passo dell’attribuzione è costruire una mappa delle entità del brand — tutte le componenti dell’organizzazione che possono essere riconosciute come entità distinte dai modelli AI.
| Tipo di entità | Esempi | Come verificare il riconoscimento |
| Brand / Azienda | Nome azienda, nome prodotto, nome servizio, acronimo | Chiedere direttamente ai modelli: “Cosa sai di [nome]?” |
| Persone chiave | CEO, fondatori, autori riconoscibili, esperti citati pubblicamente | Cercare nome + azienda nei motori generativi |
| Metodi proprietari | Framework originali, nomenclatura specifica, approcci distintivi | Chiedere “cos’è [nome metodo]?” senza contestualizzazione |
| Prodotti / Servizi | Nomi commerciali, categorie di servizio, specializzazioni verticali | Query comparative: “[prodotto] vs competitor” |
| Posizionamento geografico | Città, regione, paese — rilevante per query local | Query con modifier geografico + settore |
Il test di riconoscimento è semplice: poni ai principali modelli una domanda diretta su ciascuna entità del tuo brand (“Cosa sai dell’azienda X?”, “Chi è [nome fondatore]?”, “Cos’è il metodo [nome]?”) e analizza le risposte. Tre esiti possibili:
Entità riconosciuta con accuratezza: il modello fornisce una descrizione corretta e dettagliata. Forte associazione semantica già presente.
Entità riconosciuta parzialmente: il modello conosce il nome ma associa attributi imprecisi o incompleti. Necessità di contenuti più chiari e autorevoli.
Entità non riconosciuta: il modello non ha informazioni o le confonde con altri. Priorità assoluta di intervento.
Topic association audit: per quali argomenti sei citato?
Una volta mappate le entità del brand, il secondo passo è il topic association audit: verificare sistematicamente per quali argomenti le entità del brand vengono associate dai modelli.
Il metodo: costruire una matrice entità × topic cluster e testarla con query che forzano l’associazione. Per ogni combinazione entità-topic, la domanda di test è: “Quando chiedo ai modelli una query su [topic], citano [entità brand]?”
| Topic Cluster | Google AI | Perplexity | ChatGPT | Bing | Score medio |
| Gestione magazzino WMS | ★★★ | ★★★ | ★★ | ★★★ | 2.75 / 3 |
| Supply chain integrata | ★ | ★★ | — | ★ | 1.0 / 3 |
| Last mile delivery | — | — | — | ★ | 0.25 / 3 |
| Cold chain management | ★★ | ★ | ★ | ★★ | 1.5 / 3 |
| E-commerce fulfillment | — | ★ | — | — | 0.33 / 3 |
Tab. 14.1 — Esempio di matrice topic-association audit. ★★★ = citazione come fonte primaria, ★★ = citazione con attributo, ★ = menzione, — = assente. Dati illustrativi.
Gap identification: dove costruire nuova autorità
Il topic association audit produce la mappa del presente. Il gap identification la trasforma in una mappa del futuro: dove esistono opportunità di attribuzione non ancora sfruttate?
I gap si classificano in tre categorie, con priorità di intervento diversa.
Gap ad alto valore commerciale: topic su cui il brand ha offerta di servizio reale ma associazione generativa debole o assente. Nell’esempio della tabella, “last mile delivery” e “e-commerce fulfillment” rientrano in questa categoria se l’azienda offre questi servizi. Priorità massima: ogni investimento in contenuti su questi topic ha impatto diretto sulla pipeline.
Gap difensivi: topic su cui un competitor è già ben posizionato. Il rischio è che la domanda di mercato su quel topic venga interamente associata al competitor. L’intervento è urgente anche se il topic non è prioritario internamente.
Gap di espansione: topic adiacenti al core business, con potenziale di mercato e coerenza con il posizionamento del brand. L’investimento ha un orizzonte temporale più lungo ma costruisce topical authority strutturale nei modelli.
La decisione su quale gap affrontare per primo dipende da tre variabili: valore commerciale del topic, competitività attuale (quanto è difficile costruire associazione rispetto ai player esistenti) e coerenza con il posizionamento strategico del brand.
Ottimizzare per l’attribuzione: content signals che funzionano
Una volta identificati i gap prioritari, la domanda operativa è: come si costruisce attribuzione per un topic su cui i modelli non ti associano ancora?
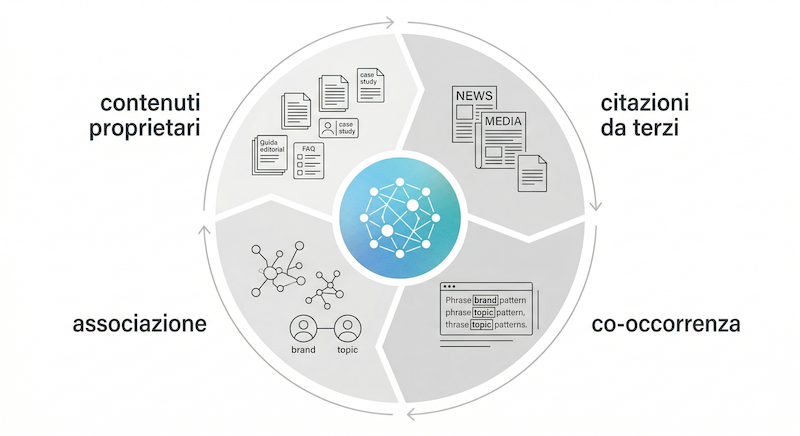
I modelli linguistici apprendono le associazioni da tre categorie di segnali, in ordine decrescente di peso.
Co-occorrenza entità-topic nei testi: ogni volta che il nome del brand e il topic target appaiono nello stesso documento — specialmente in frasi che stabiliscono esplicitamente una relazione (“Azienda X è specializzata in…”, “il metodo di Azienda X per il last mile delivery…”) — la forza dell’associazione aumenta.
Citazioni da fonti autorevoli: un articolo su una testata di settore che menziona il brand nel contesto di un topic vale molto più di 10 pagine del proprio sito sullo stesso argomento. I modelli pesano diversamente le fonti in base alla loro reputazione. Media coverage, casi studio pubblicati da terzi, menzioni in report di settore.
Volume e profondità dei contenuti proprietari: avere 15 contenuti approfonditi su un topic — pillar page, casi studio, FAQ, guide pratiche, interviste — costruisce nel tempo un segnale di topical authority che i modelli riconoscono come specializzazione reale.
Attribuzione per piattaforma: differenze tra i modelli
Non tutti i modelli costruiscono le stesse associazioni. La mappa di attribuzione di un brand può variare significativamente tra Google AI Mode, Perplexity, ChatGPT e Bing Copilot — per tre ragioni fondamentali.
Dati di training diversi: ogni modello è stato addestrato su dataset con pesi e selezioni diverse. Fonti che hanno grande rappresentanza nell’indice di Bing possono essere sottorappresentate nel training di GPT-4, e viceversa.
Architettura RAG diversa: Perplexity esegue retrieval in tempo reale e può aggiornare le associazioni più velocemente di modelli con training meno frequente. Questo significa che contenuti pubblicati recentemente su un topic possono influenzare Perplexity prima degli altri motori.
Diversa gestione delle entità ambigue: quando il nome del brand è simile a quello di un’altra entità (omonimia, acronimi condivisi, settori diversi), i modelli risolvono l’ambiguità in modo diverso. Alcune piattaforme usano il contesto della query, altre la frequenza di occorrenza nei dati di training.
L’implicazione pratica è che il topic association audit va eseguito per piattaforma e non in forma aggregata. Un brand può essere fortemente associato a un topic su Perplexity e invisibile su Google AI Mode per lo stesso topic — richiedendo interventi su fonti e contenuti diversi.
Connessioni con il framework di misurazione e il reverse engineering
L’attribuzione di query ed entità si colloca al centro del framework di misurazione GEO. I dati raccolti attraverso il sistema di tracking del capitolo precedente (→ Cap. 13) forniscono la materia prima grezza — le citazioni rilevate. L’attribuzione le trasforma in insight strutturati per argomento, entità e piattaforma.
I risultati dell’attribuzione alimentano direttamente il processo di reverse engineering della GEO (→ Cap. 15), dove le associazioni rilevate vengono usate per comprendere il comportamento dei modelli e anticipare le loro risposte prima di pubblicare nuovi contenuti.
A monte, l’attribuzione informa la content strategy per gli LLM (→ Cap. 11) — i gap identificati diventano le priorità editoriali del trimestre successivo, con focus specifico sui topic e le entità da rafforzare nei modelli.
| 🗺️ Costruisci la mappa di attribuzione del tuo brand
Il topic association audit può essere iniziato oggi con gli strumenti già disponibili. Bastano 3 ore: scegli 5-8 topic core del tuo settore, costruisci 3 query per ciascuno, testale sui 4 principali motori generativi e registra i risultati nella matrice. Il pattern emergerà chiaramente già dalla prima sessione di analisi. |
Attribuzione temporale: come cambia nel tempo
Le associazioni semantiche nei modelli non sono statiche. I modelli vengono aggiornati — con frequenza variabile a seconda della piattaforma — e nuovi contenuti, citazioni da terzi e cambiamenti nel panorama competitivo possono modificare le attribuzioni nel tempo.
Perplexity, con retrieval in tempo reale, può riflettere nuove associazioni in settimane. Modelli come GPT-4 e Gemini, con cicli di training meno frequenti, aggiornano le associazioni su orizzonti di mesi. Questo crea una dinamica strategica importante: investire oggi in contenuti e citazioni su un topic produce effetti nei modelli su orizzonti diversi per piattaforma.
Il tracking longitudinale dell’attribuzione permette di misurare l’efficacia degli interventi nel tempo. Se dopo 3 mesi di produzione intensiva di contenuti su “e-commerce fulfillment” il brand comincia a comparire in Perplexity ma non ancora in Google AI Mode, questo è un segnale che il segnale sta emergendo e che occorre attendere il prossimo ciclo di aggiornamento del modello Google.
La metrica operativa è il Delta di Attribuzione: variazione dello score medio nella matrice topic-association audit tra due rilevazioni (tipicamente a distanza di 3 mesi). Un delta positivo su topic target indica che la strategia sta funzionando. Un delta negativo su topic già coperti segnala erosione competitiva da investigare.
Dal dato all’azione: costruire il piano di intervento
L’output finale del processo di attribuzione è un piano di intervento prioritizzato che traduce la mappa dei gap in azioni concrete sui contenuti, le fonti e le PR.
Per ogni gap identificato come prioritario, il piano specifica:
Obiettivo di attribuzione: quale score nella matrice topic-association si vuole raggiungere entro quale orizzonte temporale
Contenuti da produrre: tipologia, profondità e formato dei contenuti ottimizzati per l’associazione entità-topic
Fonti da attivare: media di settore, associazioni di categoria, partner che possono citare il brand nel contesto del topic target
Metriche di verifica: come e quando rilevare il miglioramento dell’associazione nella matrice
Questo piano si integra con il budget editoriale e con le attività di PR, trasformando la GEO da attività tattica isolata a componente strutturale della strategia di marketing.
| → Prossimo capitolo: Reverse Engineering della GEO
Il Capitolo 15 — Simulare il Sistema (→ Cap. 15) porta le tecniche di attribuzione a un livello superiore: invece di misurare passivamente dove si è citati, si simula attivamente il comportamento dei modelli per anticipare quali contenuti verranno citati prima di pubblicarli. Il reverse engineering è la frontiera più avanzata della GEO. |
| ❓ FAQ — Domande frequenti sull’attribuzione GEO
Cos’è l’attribuzione di query ed entità nella GEO? L’attribuzione di query ed entità è il processo che identifica per quali argomenti e in quale contesto i motori generativi associano il brand come fonte rilevante. Mentre il citation rate misura quante volte si viene citati, l’attribuzione risponde a “per quale topic” e “in quale contesto semantico“. Permette di trasformare dati grezzi di monitoraggio in una mappa strategica delle opportunità di visibilità generativa. Come si costruisce la mappa di attribuzione di un brand? La mappa si costruisce in tre passi: entity mapping (identificare tutte le entità del brand riconoscibili dai modelli: nome azienda, persone chiave, metodi proprietari, prodotti), topic association audit (testare sistematicamente per quali topic cluster queste entità vengono citate nei motori generativi), gap identification (classificare i topic dove il brand non è ancora associato in: alto valore commerciale, difensivi, di espansione). Perché l’attribuzione varia tra Google AI Mode, Perplexity e ChatGPT? I diversi motori generativi costruiscono associazioni diverse per tre ragioni: dataset di training con pesi e selezioni diverse, architettura RAG diversa (Perplexity aggiorna in real-time, altri modelli hanno cicli di training meno frequenti), modalità diverse di gestione delle entità ambigue. Il topic association audit va quindi eseguito per piattaforma separatamente. Quali contenuti costruiscono attribuzione entità-topic più efficacemente? Tre categorie di segnali, in ordine di efficacia: co-occorrenza esplicita nei testi (frasi che stabiliscono la relazione tra brand e topic), citazioni da fonti terze autorevoli (media di settore, report, casi studio pubblicati da partner), volume e profondità dei contenuti proprietari (pillar page, FAQ, guide, interviste — almeno 10-15 pezzi su ogni topic target per costruire topical authority riconosciuta dai modelli). Quanto tempo ci vuole per costruire nuova attribuzione su un topic? L’orizzonte temporale varia per piattaforma. Perplexity, con retrieval in real-time, può riflettere nuove associazioni in 2-6 settimane. Modelli come GPT-4 e Gemini, con cicli di training meno frequenti, aggiornano le associazioni su orizzonti di 3-9 mesi. La strategia ottimale è iniziare con contenuti ottimizzati per il retrieval real-time di Perplexity, poi consolidare con attività PR e contenuti di lungo periodo per i modelli con training periodico. |
| { } Schema Markup — FAQ (JSON-LD)
{ “@context”: “https://schema.org”, “@type”: “FAQPage”, “mainEntity”: [ { “@type”: “Question”, “name”: “Cos’è l’attribuzione di query ed entità nella GEO?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “L’attribuzione di query ed entità identifica per quali argomenti i motori generativi associano il brand come fonte rilevante. Mentre il citation rate misura quante volte si viene citati, l’attribuzione risponde ‘per quale topic’ e ‘in quale contesto semantico’.” } }, { “@type”: “Question”, “name”: “Come si costruisce la mappa di attribuzione di un brand?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “In tre passi: entity mapping (identificare le entità del brand riconoscibili dai modelli), topic association audit (testare per quali topic queste entità vengono citate nei motori generativi), gap identification (classificare i topic mancanti per priorità commerciale).” } } ]} |
Appendice A — Link interni: anchor e motivazioni
| Cap. | Anchor usato | Motivazione editoriale |
| 13 | “sistema di tracking del capitolo precedente” | I dati di citation tracking raccolti in Cap. 13 sono la materia prima dell’attribuzione per intent |
| 15 | “reverse engineering della GEO” | L’attribuzione entità-topic alimenta il processo di simulazione del comportamento dei modelli in Cap. 15 |
| 11 | “content strategy per gli LLM” | I gap di attribuzione identificati diventano le priorità editoriali trattate in Cap. 11 |
| 15 | “Capitolo 15 — Simulare il Sistema” (nel CTA finale) | Invito alla lettura sequenziale del capitolo seguente della Parte IV |
Appendice B — Fonti citate
| # | Autore / Organizzazione | Titolo | Anno |
| [1] | Google / DeepMind | Gemini Technical Report — Knowledge Representation and Entity Understanding | 2024 |
| [2] | Aggarwal et al. | GEO: Generative Engine Optimization — arXiv:2311.09735 | 2023 |
| [3] | Wikidata / Knowledge Graph Community | Entity Linking in Large Language Models: A Survey | 2024 |
| [4] | Semrush Research | Entity-Based SEO: How AI Models Associate Brands with Topics | 2024 |